So I built a typing game. It’s called Train Typing, it’s free, no ads, no sign-up, recommended for kids 3 and up, and it’s live at type.avtomatik.org if you just want to go play with it.
But honestly the game itself isn’t really what I want to write about. What I want to write about is what building it taught me about working with LLMs right now, in mid-2026, vs even a year ago.
Why I built it
Every “educational” typing app I tried was either packed with ads or wanted a subscription before showing me letter C. So I just built my own. Took about a week, which is more than I expected going in. That gap between “this should take a day or two” and “okay it’s actually been a week” is kind of the whole point of this post.
It’s not “ask the model” anymore, it’s a process
A year or two ago, working with an LLM felt like one long conversation. Describe what you want, get code, fix what’s broken, repeat. Building this thing, it didn’t feel like that at all. It felt more like running an actual process, where the model is one part of it, not the whole thing.
There’s a pattern to how it goes now: understand what I’m asking for, ask me questions if I’m being vague, do the work, check the work actually works, write down what it learned, move on. Same shape, session after session. Stopped feeling like a coincidence pretty fast.
A few things I noticed:
It asks a lot of clarifying questions. Sometimes annoyingly many. But more than once it asked something and I realized I hadn’t actually decided what I wanted yet. So, fine, fair.
Way less hallucinating than last year, but it still lies sometimes. It’ll still confidently tell you something works when it doesn’t. The difference is it gets caught more now — by tests, by it double-checking itself, by the process. Not because it suddenly got more honest.
It corrects itself without being told to. This is the biggest change for me. After building something it does its own little postmortem — did this actually work, what did I assume wrong, what should I fix. Caught real bugs this way that I never had to point out myself.
Gets stuck in dead loops less. That thing where it keeps repeating the same wrong fix over and over — still happens, just less than before, and it’s easier to snap out of when it does.
Edge cases are still genuinely hard. This is the honest caveat. The everyday stuff — features, fixes, refactors — is in a really good place now. But the weird corners are still weird. I hit a few CSS/layout edge cases during this build that took real back-and-forth to nail down, and even the Claude UI itself has bugs that go unnoticed for a while. Edge cases being hard isn’t unique to LLMs, it’s true of software in general, but it’s worth saying plainly: “really good at the common case” and “good at everything” are still two different claims.
Increasing the Reasoning levels doesn’t help as much as you’ve thought. You burn the same tokens for the same result.
None of this means you can just trust it blindly. It means the process around it is trustworthy in a way the model by itself still isn’t. Which, honestly, is just normal engineering: don’t trust the component, build something that catches the component being wrong.
What actually went into this thing
A week, and it covered way more ground than just “write some code”:
- Real tests, both for the Rust side and the JS side
- A proper deploy pipeline, zero downtime, with cache purging and all that
- Screenshots, a demo GIF, social posts, an Open Graph preview image, this post
- Game logic is Rust compiled to WASM, the JS layer on top is just plain vanilla JS, no framework
None of that existed a week ago. Not bragging about speed here — just pointing out that one person, with a process like this behind them, can cover a lot more ground in a week than felt normal not long ago.
2000s vs now
This part surprised me the most. Building this reminded me of when I first started messing with Linux and web stuff in the early 2000s. That feeling of “I can just build the whole thing myself and ship it.” Back then it really was: get a VPS, install LAMP, done. Genuinely easy.
What’s different now isn’t getting an idea into working code — if anything that part’s easier than ever. What’s different is everything around it. Mobile compatibility took longer when I though (e.g. Virtual keyboard implementation). Security expectations. Caching correctly. The number of devices a thing needs to actually work on before it’s “done.” The floor dropped, sure, anyone can get something running fast now. But the bar for doing it properly went up, not down. A good LLM-driven process closes a lot of that gap. Not all of it.
Go try the actual game
If you’ve got a kid 3 or older, give it a go: type.avtomatik.org. Animals, letters, numbers, full sound, works on phone or computer, no install, no ads, no account.

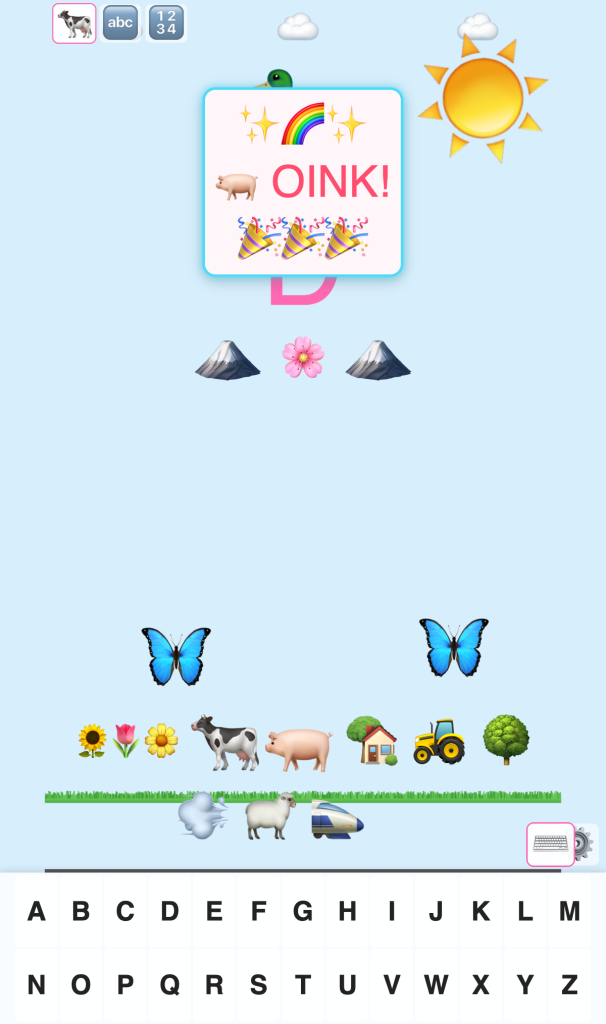

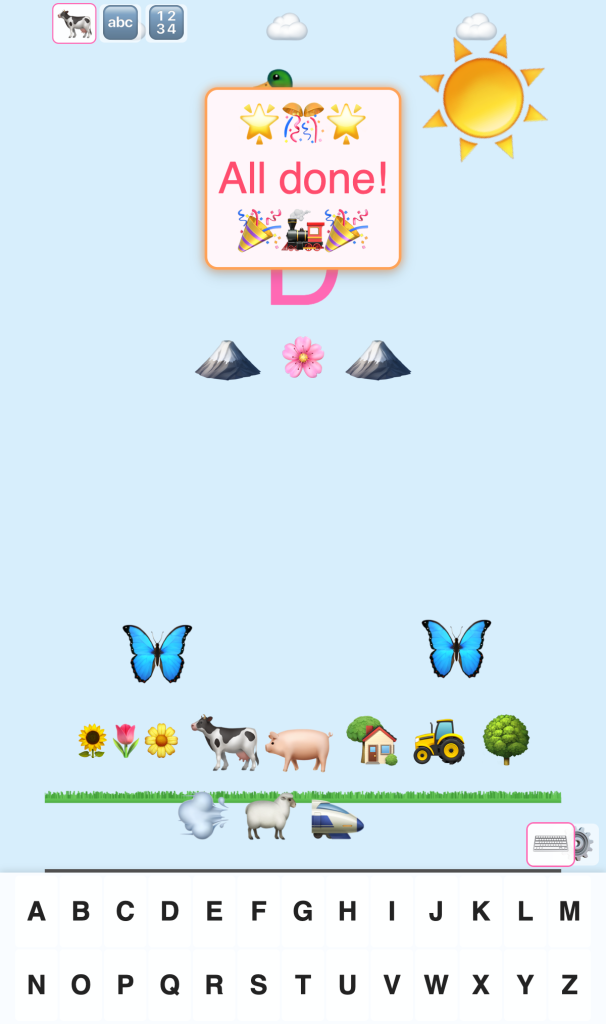
If the engineering side is more your thing — the virtual keyboard implementation struggle, the deploy pipeline — happy to talk through any of it in the comments.
TLDR;
Still not perfect but already much better when it was. Especially with lesser hallucinations. Though too much thinking and constant disconnects are disappointing.
P.S.: One caveat before I sign off: I haven’t tried the new Mythos model yet, so everything above is based on models from the 4.5 generation onward — which, for what it’s worth, have all been genuinely good to work with.
Let the Force be with you!
And, as usual, your VR